When we use tools like Skype and QQ to smoothly conduct voice and video chats with friends, have we ever wondered what powerful technologies are behind it? This article will give a brief introduction to the technologies used in network voice calls, which can be regarded as a glimpse of the leopard.
1. Conceptual model
Internet voice calls are usually two-way, which is symmetrical at the model level. For the sake of simplicity, we can discuss the channel in one direction. One party speaks and the other party hears the voice. It seems simple and fast, but the process behind it is quite complicated.
This is the most basic model consisting of five important links: acquisition, encoding, transmission, decoding, and playback.
(1) Voice collection
Voice collection refers to the collection of audio data from a microphone, that is, the conversion of sound samples into digital signals. It involves several important parameters: sampling frequency, number of sampling bits, and number of channels.
To put it simply: the sampling frequency is the number of acquisition actions in 1 second; the number of sampling bits is the length of the data obtained for each acquisition action.
The size of an audio frame is equal to: (sampling frequency × number of sampling bits × number of channels × time)
Usually, the duration of a sampling frame is 10ms, that is, every 10ms of data constitutes an audio frame. Assuming: the sampling rate is 16k, the number of sampling bits is 16bit, and the number of channels is 1, then the size of a 10ms audio frame is: (16000*16*1*0.01)/8 = 320 bytes. In the calculation formula, 0.01 is a second, that is, 10ms.
(2) Coding
Assuming that we send the collected audio frame directly without encoding, then we can calculate the required bandwidth requirement. Still the above example: 320*100 = 32KBytes/s, if converted to bits/s, it is 256kb/ s. This is a lot of bandwidth usage. With network traffic monitoring tools, we can find that when voice calls are made with IM software like QQ, the traffic is 3-5KB/s, which is an order of magnitude smaller than the original traffic. This is mainly due to audio coding technology. Therefore, in the actual voice call application, this link of coding is indispensable. There are many commonly used speech coding technologies, such as G.729, iLBC, AAC, SPEEX and so on.
(3) Network transmission
When an audio frame is encoded, it can be sent to the caller via the network. For Realtime applications such as voice conversations, low latency and stability are very important, which requires our network to transmit very smoothly.
(4) Decoding
When the other party receives the encoded frame, it will decode it to restore it to data that can be played directly by the sound card.
(5) Voice playback
After the decoding is completed, the obtained audio frame can be submitted to the sound card for playback. Attachment: You can refer to the introduction and demo source code and SDK download of MPlayer, a voice playback component
2. Difficulties and solutions in practical applications
If only relying on the above-mentioned technology can realize a sound dialogue system applied to the wide area network, then there is not much need to write this article. It is precisely that many realistic factors have introduced many challenges for the above-mentioned conceptual model, which makes the realization of the network voice system not so simple, which involves many professional technologies. Of course, most of these challenges already have mature solutions. First of all, we need to define a "good effect" voice dialogue system. I think it should achieve the following points:
(1) Low latency. Only with low latency can the two parties on the call have a strong sense of Realtime. Of course, this mainly depends on the speed of the network and the distance between the physical locations of the two parties on the call. From the perspective of pure software, the possibility of optimization is very small.
(2) Low background noise.
(3) The sound is smooth, without the feeling of stuck or pause.
(4) There is no response.
Below we will talk about the additional technologies used in the actual network voice dialogue system one by one.
1. Echo cancellation AEC Almost everyone is now accustomed to directly using the PC or notebook voice playback function during voice chat. As everyone knows, this little habit has posed a big challenge for voice technology. When using the loudspeaker function, the sound played by the speaker will be collected by the microphone again and transmitted back to the other party, so that the other party can hear their own echo. Therefore, in practical applications, the function of echo cancellation is necessary. After the collected audio frame is obtained, this gap before encoding is the time for the echo cancellation module to work. The principle is simply that the echo cancellation module performs some cancellation-like operations in the collected audio frame according to the audio frame just played, so as to remove the echo from the collected frame. This process is quite complicated, and it is also related to the size of the room you are in when you are chatting, and your location in the room, because this information determines the length of the sound wave reflection. The intelligent echo cancellation module can dynamically adjust the internal parameters to best adapt to the current environment.
2. Noise suppression DENOISE Noise suppression, also known as noise reduction processing, is based on the characteristics of voice data to identify the part of background noise and filter it out of audio frames. Many encoders have this feature built in.
3. JitterBuffer The jitter buffer is used to solve the problem of network jitter. The so-called network jitter means that the network delay will be larger and smaller. In this case, even if the sender sends data packets regularly (for example, a packet is sent every 100ms), the receiver cannot receive the same timing. Sometimes No packet can be received in a cycle, and sometimes several packets are received in a cycle. In this way, the sound that the receiver hears is one card one card. JitterBuffer works after the decoder and before the voice playback. That is, after the speech decoding is completed, the decoded frame is put into the JitterBuffer, and when the playback callback of the sound card arrives, the oldest frame is retrieved from the JitterBuffer for playback. The buffer depth of JitterBuffer depends on the degree of network jitter. The greater the network jitter, the greater the buffer depth and the greater the delay in playing audio. Therefore, JitterBuffer uses a higher delay in exchange for smooth sound playback, because compared to the sound one card one card, a slightly larger delay but a smoother effect, its subjective experience is better. Of course, the buffer depth of JitterBuffer is not constant, but dynamically adjusted according to changes in the degree of network jitter. When the network is restored to be very smooth and unobstructed, the buffer depth will be very small, so that the increase in playback delay due to JitterBuffer will be negligible.
4. Mute detection VAD In a voice conversation, if one party is not speaking, no traffic will be generated. Mute detection is used for this purpose. Mute detection is usually also integrated in the encoding module. The silent detection algorithm combined with the previous noise suppression algorithm can identify whether there is voice input currently. If there is no voice input, it can encode and output a special coded frame (for example, the length is 0). Especially in a multi-person video conference, usually only one person is speaking. In this case, the use of silent detection technology to save bandwidth is still very considerable.
5. Mixing algorithm In a multi-person voice chat, we need to play voice data from multiple people at the same time, and the sound card plays only one buffer. Therefore, we need to mix multiple voices into one. This is what the mixing algorithm does. Even if you can find a way to bypass the mixing and let multiple sounds play at the same time, then for the purpose of echo cancellation, it must be mixed into one playback, otherwise, echo cancellation can only eliminate some of the multiple sounds at most. All the way. Mixing can be done on the client side or on the server side (which can save downstream bandwidth). If P2P channels are used, then mixing can only be done on the client side. If it is mixing on the client, usually, mixing is the last link before playing. This article is a rough summary of our experience in implementing the voice part of OMCS. Here, we just made a simple description of each link in the figure, and any one of them can be written into a long paper or even a book. Therefore, this article is just to provide an introductory map for those who are new to network voice system development, and give some clues.



|
|
|
|
How far(long) the transmitter cover?
The transmission range depends on many factors. The true distance is based on the antenna installing height , antenna gain, using environment like building and other obstructions , sensitivity of the receiver, antenna of the receiver . Installing antenna more high and using in the countryside , the distance will much more far.
EXAMPLE 5W FM Transmitter use in the city and hometown:
I have a USA customer use 5W fm transmitter with GP antenna in his hometown ,and he test it with a car, it cover 10km(6.21mile).
I test the 5W fm transmitter with GP antenna in my hometown ,it cover about 2km(1.24mile).
I test the 5W fm transmitter with GP antenna in Guangzhou city ,it cover about only 300meter(984ft).
Below are the approximate range of different power FM Transmitters. ( The range is diameter )
0.1W ~ 5W FM Transmitter :100M ~1KM
5W ~15W FM Ttransmitter : 1KM ~ 3KM
15W ~ 80W FM Transmitter : 3KM ~10KM
80W ~500W FM Transmitter : 10KM ~30KM
500W ~1000W FM Transmitter : 30KM ~ 50KM
1KW ~ 2KW FM Transmitter : 50KM ~100KM
2KW ~5KW FM Transmitter : 100KM ~150KM
5KW ~10KW FM Transmitter : 150KM ~200KM
How to contact us for the transmitter?
Call me +8618078869184 OR
whatsapp:+86 18319244009
Email me [email protected]
1.How far you want to cover in diameter ?
2.How tall of you tower ?
3.Where are you from ?
And we will give you more professional advice.
About Us
FMUSER.ORG is a system integration company focusing on RF wireless transmission / studio video audio equipment / streaming and data processing .We are providing everything from advice and consultancy through rack integration to installation, commissioning and training.
We offer FM Transmitter, Analog TV Transmitter, Digital TV transmitter, VHF UHF Transmitter, Antennas, Coaxial Cable Connectors, STL, On Air Processing, Broadcast Products for the Studio, RF Signal Monitoring, RDS Encoders, Audio Processors and Remote Site Control Units, IPTV Products, Video / Audio Encoder / Decoder, designed to meet the needs of both large international broadcast networks and small private stations alike.
Our solution has FM Radio Station / Analog TV Station / Digital TV Station / Audio Video Studio Equipment / Studio Transmitter Link / Transmitter Telemetry System / Hotel TV System / IPTV Live Broadcasting / Streaming Live Broadcast / Video Conference / CATV Broadcasting system.
We are using advanced technology products for all the systems, because we know the high reliability and high performance are so important for the system and solution . At the same time we also have to make sure our products system with a very reasonable price.
We have customers of public and commercial broadcasters, telecom operators and regulation authorities , and we also offer solution and products to many hundreds of smaller, local and community broadcasters .
FMUSER.ORG has been exporting more than 15 years and have clients all over the world. With 13 years experience in this field ,we have a professional team to solve customer's all kinds of problems. We dedicated in supplying the extremely reasonable pricing of professional products & services. Contact email : [email protected]
Our Factory

We have modernization of the factory . You are welcome to visit our factory when you come to China.

At present , there are already 1095 customers around the world visited our Guangzhou Tianhe office . If you come to China , you are welcome to visit us .
At Fair

This is our participation in 2012 Global Sources Hong Kong Electronics Fair . Customers from all over the world finally have a chance to get together.
Where is Fmuser ?
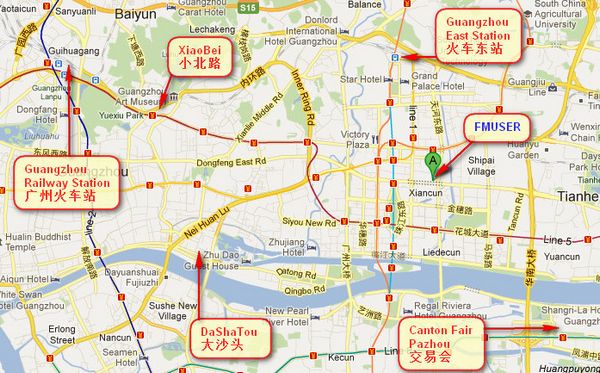
You can search this numbers " 23.127460034623816,113.33224654197693 " in google map , then you can find our fmuser office .
FMUSER Guangzhou office is in Tianhe District which is the center of the Canton . Very near to the Canton Fair , guangzhou railway station, xiaobei road and dashatou , only need 10 minutes if take TAXI . Welcome friends around the world to visit and negotiate .
Contact: Kerwin
Cellphone: +8618078869184
whatsapp:+86 18319244009
Wechat: +8618078869184
E-mail: [email protected]
Address: No.305 Room HuiLan Building No.273 Huanpu Road Guangzhou China Zip:510620
|
|
|
|
English: We accept all payments , such as PayPal, Credit Card, Western Union, Alipay, Money Bookers, T/T, LC, DP, DA, OA, Payoneer, If you have any question , please contact me [email protected] or
whatsapp:+86 18319244009
-
PayPal.  www.paypal.com www.paypal.com
We recommend you use Paypal to buy our items ,The Paypal is a secure way to buy on internet .
Every of our item list page bottom on top have a paypal logo to pay.
Credit Card.If you do not have paypal,but you have credit card,you also can click the Yellow PayPal button to pay with your credit card.
---------------------------------------------------------------------
But if you have not a credit card and not have a paypal account or difficult to got a paypal accout ,You can use the following:
Western Union.  www.westernunion.com www.westernunion.com
Pay by Western Union to me :
First name/Given name: Yingfeng
Last name/Surname/ Family name: Zhang
Full name: Yingfeng Zhang
Country: China
City: Guangzhou
|
---------------------------------------------------------------------
T/T . Pay by T/T (wire transfer/ Telegraphic Transfer/ Bank Transfer)
First BANK INFORMATION (COMPANY ACCOUNT):
SWIFT BIC: BKCHHKHHXXX
Bank name: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Bank Address: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
BANK CODE: 012
Account Name : FMUSER INTERNATIONAL GROUP LIMITED
Account NO. : 012-676-2-007855-0
---------------------------------------------------------------------
Second BANK INFORMATION (COMPANY ACCOUNT):
Beneficiary: Fmuser International Group Inc
Account Number: 44050158090900000337
Beneficiary's Bank: China Construction Bank Guangdong Branch
SWIFT Code: PCBCCNBJGDX
Address: NO.553 Tianhe Road, Guangzhou, Guangdong,Tianhe District, China
**Note: When you transfer money to our bank account, please DO NOT write anything in the remark area, otherwise we won't be able to receive the payment due to government policy on international trade business.
|
|
|
|
* It will be sent in 1-2 working days when payment clear.
* We will send it to your paypal address. If you want to change address, please send your correct address and phone number to my email [email protected]
* If the packages is below 2kg,we will be shipped via post airmail, it will take about 15-25days to your hand.
If the package is more than 2kg,we will ship via EMS , DHL , UPS, Fedex fast express delivery,it will take about 7~15days to your hand.
If the package more than 100kg , we will send via DHL or air freight. It will take about 3~7days to your hand.
All the packages are form China guangzhou.
* Package will be sent as a "gift" and declear as less as possible,buyer don't need to pay for "TAX".
* After ship, we will send you an E-mail and give you the tracking number.
|
|
|
For Warranty .
Contact US--->>Return the item to us--->>Receive and send another replace .
Please return to this address and write your paypal address,name,problem on note: |
|













