(1) Redundant information of video signal
Taking the YUV component format of recording digital video as an example, YUV represents brightness and two color difference signals respectively. For example, for existing pal TV system, the sampling frequency of luminance signal is 13.5mhz; the frequency band of chroma signal is usually half or less of the brightness signal, which is 6.75mhz or 3.375mhz. Taking the sampling frequency of 4:2:2 as an example, Y signal adopts 13.5mhz, chroma signal U and V are sampled by 6.75mhz, and the sampling signal is quantized by 8bit, then the code rate of digital video can be calculated as follows:
13.5*8 + 6.75*8 + 6.75*8= 216Mbit/s
If such a large amount of data is stored or transmitted directly, it will be difficult to use compression technology to reduce the bit rate. The digital video signal can be compressed according to two basic conditions:
L. data redundancy. For example, spatial redundancy, time redundancy, structure redundancy, information entropy redundancy, etc., that is, there is a strong correlation between pixels of the image. Eliminating these redundancy does not lead to information loss, and it is lossless compression.
L. visual redundancy. Some characteristics of human eyes, such as brightness discrimination threshold, visual threshold, are different in sensitivity to brightness and chroma, which makes it impossible to introduce appropriate errors in coding and will not be detected. The visual characteristics of human eyes can be used to exchange for data compression with certain objective distortion. This compression is lossy.
The compression of digital video signal is based on the above two conditions, which makes the video data greatly compressed, which is conducive to transmission and storage. The common methods of digital video compression are mixed coding, which is to combine transform coding, motion estimation and motion compensation, and entropy coding to compress coding. Usually, transform coding is used to eliminate the intra frame redundancy of the image, and motion estimation and motion compensation are used to remove the inter frame redundancy of the image, and entropy coding is used to further improve the compression efficiency. The following three compression coding methods are introduced briefly.
(a) Compression coding method
(b) Transform coding
The function of transform coding is to transform the image signal described in the space domain to the frequency domain, and then encode the transformed coefficients. Generally speaking, the image has strong correlation in space, and the transformation to frequency domain can realize decorrelation and energy concentration. The common orthogonal transform includes discrete Fourier transform, discrete cosine transform and so on. Discrete cosine transform is widely used in digital video compression.
Discrete cosine transform is referred to as DCT transform. It can transform the image block of L * l from space domain to frequency domain. Therefore, in the process of image compression and coding based on DCT, the image needs to be divided into non overlapping image blocks. Suppose the size of an image is 1280 * 720, it is divided into 160 * 90 image blocks with 8 * 8 size without overlapping in the form of grid. Then DCT transformation can be performed for each image block.
After the block is divided, each 8 * 8 point image block is sent to DCT encoder, and the 8 * 8 image block is transformed from the spatial domain to the frequency domain. The figure below shows an example of an image block of 8 * 8 in which the number represents the brightness value of each pixel. It can be seen from the figure that the brightness values of each pixel in this image block are relatively uniform, especially the brightness value of adjacent pixels is not very large, which indicates that the image signal has a strong correlation.
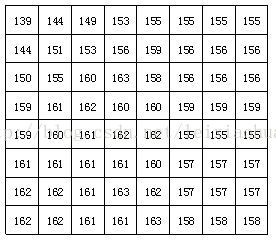
An actual 8 * 8 image block
The following figure shows the results of DCT transformation of the image block in the above figure. It can be seen from the figure that after DCT transformation, the low frequency coefficient in the upper left corner concentrates a lot of energy, while the energy on the high frequency coefficient in the lower right corner is very small.
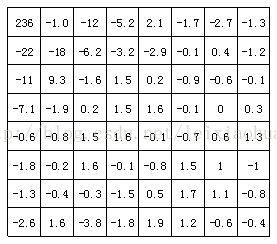
The coefficients of image block after DCT transformation
The signal needs to be quantified after DCT transformation. Because human eyes are sensitive to low frequency characteristics of images, such as the overall brightness of objects, and not to the high-frequency details in the image, so in the transmission process, high-frequency information can be transmitted less or not, only the low-frequency part. The quantization process reduces the information transmission by quantifying the coefficients of low frequency region and coarse quantization of the coefficients in high frequency region, which removes the high-frequency information which is not sensitive to human eyes. Therefore, quantization is a lossy compression process and the main reason for the quality damage in video compression coding.
The quantification process can be expressed by the following formula:

Among them, FQ (U, V) represents the DCT coefficient after quantization; f (U, V) represents DCT coefficient before quantization; Q (U, V) represents quantization weighting matrix; q is quantization step; round refers to consolidation, and the value to be output is taken as the closest integer value.
Select the quantization coefficient reasonably, and the result after quantizing the transformed image block is shown in the figure.

DCT coefficient after quantification
Most of DCT coefficients are changed to 0 after quantization, while only a few coefficients are non-zero values. At this time, only these non-zero values need to be compressed and encoded.
(b) Entropy coding
Entropy coding is named because the average code length after coding is close to the entropy value of source. Entropy coding is implemented by VLC (variable length coding). The basic principle is to give short code to the symbol with high probability in the source, and to give long code to the symbol with small probability of occurrence, so as to obtain the shorter average code length statistically. Variable length coding usually includes Hoffman code, arithmetic code, run code, etc. Run length coding is a very simple compression method, its compression efficiency is not high, but the coding and decoding speed is fast, and it is still widely used, especially after the transformation of the encoding, using run-length coding, has a good effect.
First, the AC coefficient immediately following the output DC coefficient of the quantizer shall be scanned in Z-type (as shown in the arrow line). The Z-scan transforms the two-dimensional quantization coefficient into one-dimensional sequence, and then carries on the run length coding. Finally, another variable length code is used to encode the data after the run encoding, such as Hoffman coding. Through this kind of variable length coding, the efficiency of coding is further improved.
(c) Motion estimation and motion compensation
Motion estimation and motion compensation are effective methods to eliminate the correlation of time direction of image sequences. The DCT transform, quantization and entropy coding methods described above are based on one frame image. Through these methods, the spatial correlation between pixels in the image can be eliminated. In fact, in addition to spatial correlation, image signal has temporal correlation. For example, for digital video with background static like news co broadcasting and small movement of main body of picture, the difference between each picture is very small, and the correlation between images is very big. In this case, we do not need to encode each frame image separately, but can only encode the changed parts of adjacent video frames, so as to further reduce the data amount. This work is realized by motion estimation and motion compensation.
Motion estimation technology generally divides the current input image into several small image sub blocks which do not overlap each other, for example, the size of a frame image is 1280 * 720. Firstly, it is divided into 40 * 45 image blocks with 16 * 16 size that do not overlap each other in the form of grid, and then, within the scope of a search window of the previous image or the latter image, find a block for each image block to find one image block within the scope of a search window The most similar image block. The search process is called motion estimation. By calculating the position information between the most similar image block and the image block, a motion vector can be obtained. In this way, the current image block can be subtracted from the most similar image block pointed by the reference image motion vector, and a residual image block can be obtained. Because each pixel value in the residual image block is very small, a higher compression ratio can be obtained in compression coding. This subtraction process is called motion compensation.
Because reference image is needed to be used for motion estimation and motion compensation in the coding process, it is very important to select reference image. Generally, the encoder divides each frame image input into three different types according to the different reference images: I (intra) frame, B (guidance prediction) frame and P (prediction) frame. As shown in the figure.
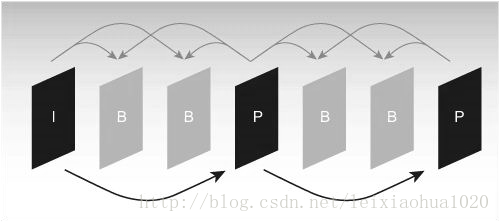
Typical I, B, P frame structure sequence
As shown in the figure, I frame only uses the data in the frame for coding, and it does not need motion estimation and motion compensation during the coding process. Obviously, since I frame does not eliminate the correlation of time direction, the compression ratio is relatively low. In the process of coding, P frame uses a front I frame or P frame as the reference image for motion compensation, in fact, it encodes the difference between the current image and the reference image. The encoding mode of B frame is similar to P frame, the only difference is that it needs to use a front I frame or P frame and a later I frame or P frame to predict during the coding process. Thus, each P frame coding needs to use one frame image as the reference image, while frame B needs two frames as reference. In contrast, B frame has a higher compression ratio than P frame.
(d) Mixed coding
The paper introduces several important methods in video compression and coding. In practical application, these methods are not separated, and they are usually combined to achieve the best compression effect. The following figure shows the model of hybrid coding (i.e. transform coding + motion estimation and motion compensation + entropy coding). The model is widely used in MPEG1, MPEG2, H.264 and other standards.From the figure, we can see that the current input image must be divided into blocks first, the block of the image obtained by the block shall be subtracted from the predicted image after motion compensation to obtain the difference image x, and then DCT transformation and quantization are carried out for the difference image block. The quantized output data has two different places: one is to send it to the entropy encoder for coding, and the encoded code stream is output to a cache Save in the device and wait for transmission. Another application is to counter quantify and reverse change to signal x ', which adds the image block output with motion compensation to obtain a new prediction image signal, and sends a new prediction image block to frame memory.



|
|
|
|
How far(long) the transmitter cover?
The transmission range depends on many factors. The true distance is based on the antenna installing height , antenna gain, using environment like building and other obstructions , sensitivity of the receiver, antenna of the receiver . Installing antenna more high and using in the countryside , the distance will much more far.
EXAMPLE 5W FM Transmitter use in the city and hometown:
I have a USA customer use 5W fm transmitter with GP antenna in his hometown ,and he test it with a car, it cover 10km(6.21mile).
I test the 5W fm transmitter with GP antenna in my hometown ,it cover about 2km(1.24mile).
I test the 5W fm transmitter with GP antenna in Guangzhou city ,it cover about only 300meter(984ft).
Below are the approximate range of different power FM Transmitters. ( The range is diameter )
0.1W ~ 5W FM Transmitter :100M ~1KM
5W ~15W FM Ttransmitter : 1KM ~ 3KM
15W ~ 80W FM Transmitter : 3KM ~10KM
80W ~500W FM Transmitter : 10KM ~30KM
500W ~1000W FM Transmitter : 30KM ~ 50KM
1KW ~ 2KW FM Transmitter : 50KM ~100KM
2KW ~5KW FM Transmitter : 100KM ~150KM
5KW ~10KW FM Transmitter : 150KM ~200KM
How to contact us for the transmitter?
Call me +8618078869184 OR
Email me [email protected]
1.How far you want to cover in diameter ?
2.How tall of you tower ?
3.Where are you from ?
And we will give you more professional advice.
About Us
FMUSER.ORG is a system integration company focusing on RF wireless transmission / studio video audio equipment / streaming and data processing .We are providing everything from advice and consultancy through rack integration to installation, commissioning and training.
We offer FM Transmitter, Analog TV Transmitter, Digital TV transmitter, VHF UHF Transmitter, Antennas, Coaxial Cable Connectors, STL, On Air Processing, Broadcast Products for the Studio, RF Signal Monitoring, RDS Encoders, Audio Processors and Remote Site Control Units, IPTV Products, Video / Audio Encoder / Decoder, designed to meet the needs of both large international broadcast networks and small private stations alike.
Our solution has FM Radio Station / Analog TV Station / Digital TV Station / Audio Video Studio Equipment / Studio Transmitter Link / Transmitter Telemetry System / Hotel TV System / IPTV Live Broadcasting / Streaming Live Broadcast / Video Conference / CATV Broadcasting system.
We are using advanced technology products for all the systems, because we know the high reliability and high performance are so important for the system and solution . At the same time we also have to make sure our products system with a very reasonable price.
We have customers of public and commercial broadcasters, telecom operators and regulation authorities , and we also offer solution and products to many hundreds of smaller, local and community broadcasters .
FMUSER.ORG has been exporting more than 15 years and have clients all over the world. With 13 years experience in this field ,we have a professional team to solve customer's all kinds of problems. We dedicated in supplying the extremely reasonable pricing of professional products & services. Contact email : [email protected]
Our Factory

We have modernization of the factory . You are welcome to visit our factory when you come to China.

At present , there are already 1095 customers around the world visited our Guangzhou Tianhe office . If you come to China , you are welcome to visit us .
At Fair

This is our participation in 2012 Global Sources Hong Kong Electronics Fair . Customers from all over the world finally have a chance to get together.
Where is Fmuser ?
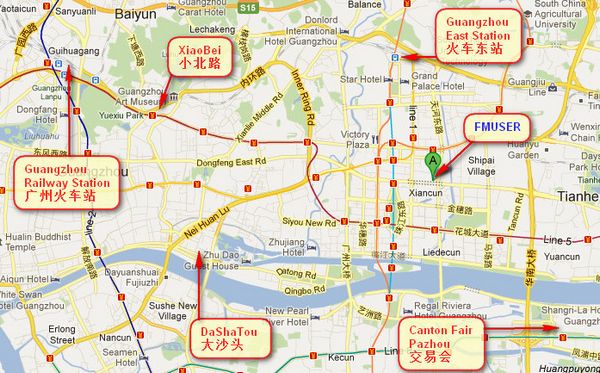
You can search this numbers " 23.127460034623816,113.33224654197693 " in google map , then you can find our fmuser office .
FMUSER Guangzhou office is in Tianhe District which is the center of the Canton . Very near to the Canton Fair , guangzhou railway station, xiaobei road and dashatou , only need 10 minutes if take TAXI . Welcome friends around the world to visit and negotiate .
Contact: Sky Blue
Cellphone: +8618078869184
WhatsApp: +8618078869184
Wechat: +8618078869184
E-mail: [email protected]
QQ: 727926717
Skype: sky198710021
Address: No.305 Room HuiLan Building No.273 Huanpu Road Guangzhou China Zip:510620
|
|
|
|
English: We accept all payments , such as PayPal, Credit Card, Western Union, Alipay, Money Bookers, T/T, LC, DP, DA, OA, Payoneer, If you have any question , please contact me [email protected] or WhatsApp +8618078869184
-
PayPal.  www.paypal.com www.paypal.com
We recommend you use Paypal to buy our items ,The Paypal is a secure way to buy on internet .
Every of our item list page bottom on top have a paypal logo to pay.
Credit Card.If you do not have paypal,but you have credit card,you also can click the Yellow PayPal button to pay with your credit card.
---------------------------------------------------------------------
But if you have not a credit card and not have a paypal account or difficult to got a paypal accout ,You can use the following:
Western Union.  www.westernunion.com www.westernunion.com
Pay by Western Union to me :
First name/Given name: Yingfeng
Last name/Surname/ Family name: Zhang
Full name: Yingfeng Zhang
Country: China
City: Guangzhou
|
---------------------------------------------------------------------
T/T . Pay by T/T (wire transfer/ Telegraphic Transfer/ Bank Transfer)
First BANK INFORMATION (COMPANY ACCOUNT):
SWIFT BIC: BKCHHKHHXXX
Bank name: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Bank Address: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
BANK CODE: 012
Account Name : FMUSER INTERNATIONAL GROUP LIMITED
Account NO. : 012-676-2-007855-0
---------------------------------------------------------------------
Second BANK INFORMATION (COMPANY ACCOUNT):
Beneficiary: Fmuser International Group Inc
Account Number: 44050158090900000337
Beneficiary's Bank: China Construction Bank Guangdong Branch
SWIFT Code: PCBCCNBJGDX
Address: NO.553 Tianhe Road, Guangzhou, Guangdong,Tianhe District, China
**Note: When you transfer money to our bank account, please DO NOT write anything in the remark area, otherwise we won't be able to receive the payment due to government policy on international trade business.
|
|
|
|
* It will be sent in 1-2 working days when payment clear.
* We will send it to your paypal address. If you want to change address, please send your correct address and phone number to my email [email protected]
* If the packages is below 2kg,we will be shipped via post airmail, it will take about 15-25days to your hand.
If the package is more than 2kg,we will ship via EMS , DHL , UPS, Fedex fast express delivery,it will take about 7~15days to your hand.
If the package more than 100kg , we will send via DHL or air freight. It will take about 3~7days to your hand.
All the packages are form China guangzhou.
* Package will be sent as a "gift" and declear as less as possible,buyer don't need to pay for "TAX".
* After ship, we will send you an E-mail and give you the tracking number.
|
|
|
For Warranty .
Contact US--->>Return the item to us--->>Receive and send another replace .
Name: Liu xiaoxia
Address: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
ZIP:510620
Phone: +8618078869184
Please return to this address and write your paypal address,name,problem on note: |
|













